ALMS and OKF: Turning Agent Experience Into Portable Knowledge
Agents do not only need better access to documentation.
They need a way to turn repeated experience into durable knowledge.
That is the gap I wanted ALMS to address with OKF. Not by replacing documentation. Not by becoming a wiki. Not by pretending every agent observation is truth.
The useful idea is narrower:
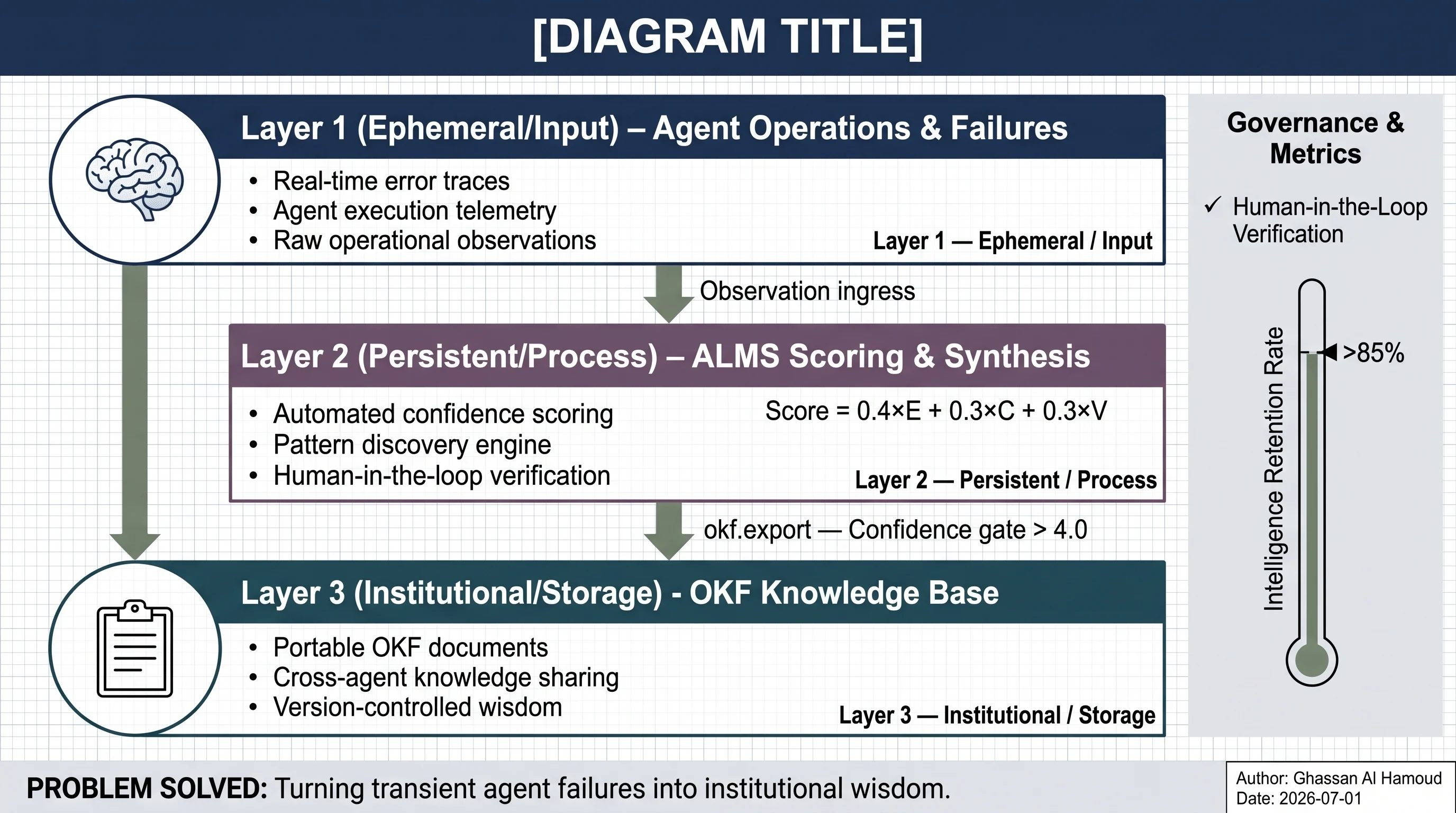
ALMS should capture operational experience. OKF should carry curated knowledge. The bridge should export selected ALMS lessons into OKF when they are mature enough to share.
That distinction matters. Without it, an agent memory system becomes a pile of anecdotes, and a knowledge format becomes another dumping ground.
The Problem: Experience Has No Promotion Path
Most agent systems already have access to knowledge.
They can read README files, API docs, runbooks, tickets, code comments, architecture notes, and vector indexes. The problem is not that context does not exist.
The problem is that agents also learn things while working:
- a retry strategy that worked for a flaky endpoint
- a migration command that fails unless an environment variable is set
- a deployment order that avoids a known race
- a confusing error message that maps to one real root cause
- a prompt pattern that consistently improves a recurring task
That information usually stays trapped in one of three places:
- the agent's short-term context
- an unstructured log
- a proprietary memory store
Even when the lesson is useful, it often has no promotion path into the organization's shared knowledge base.
So another agent repeats the same mistake later.
That is the expensive part.
OKF and ALMS Solve Different Problems
OKF, the Open Knowledge Format introduced by Google Cloud, is intentionally simple: Markdown files with YAML metadata. That makes knowledge human-readable, agent-readable, and Git-friendly.
It is a good fit for curated knowledge:
- services
- APIs
- datasets
- policies
- runbooks
- business terms
- architecture decisions
ALMS has a different job. It is a shared learning layer for agents. It stores operational lessons such as failures, patterns, edge cases, configuration findings, and protocol-related learning.
The clean separation is:
| Layer | Primary Source | Main Value | Typical Shape |
|---|---|---|---|
| OKF | Human-curated knowledge | Shared context and documentation | Markdown + YAML metadata |
| ALMS | Agent-generated experience | Reuse of lessons learned during work | Learning records with type, body, tags, status, score |
These systems should not collapse into each other.
OKF should not become a raw event log.
ALMS should not become a documentation authoring system.
The bridge exists for the narrow moment when an operational lesson is useful enough to become portable knowledge.
The Design Rule
The rule I used for the implementation is simple:
Export only selected ALMS learnings. Do not export the whole memory store.
That is why the bridge is read-only and filter-driven.
The current okf.export tool does not write files to disk. It does not commit to Git. It does not mutate ALMS records. It returns an OKF bundle payload that a caller can write, review, commit, or publish through its own workflow.
That keeps the boundary clean:
- ALMS decides which lessons are candidates.
- OKF carries the exported knowledge.
- Git or another repository remains the publication layer.
- Human review can still exist outside ALMS.
This is intentionally less ambitious than an automatic documentation generator. That is the point.

What okf.export Actually Does
The implementation is small.
okf.export searches or filters ALMS learning records and returns a file-oriented OKF bundle.
The default selection is conservative:
status:acceptedmin_score:4.0limit:50query: optionaltype: optionaltags: optionalinclude_rejected: false by default
That means callers can export a targeted bundle:
{
"query": "retry malformed JSON",
"status": "accepted",
"min_score": 4.0,
"tags": ["api"],
"limit": 50
}Or they can export by maturity and taxonomy alone:
{
"type": "pattern",
"tags": ["deployment"],
"status": "accepted",
"min_score": 4.0
}The response is not a tarball or a directory write. It is a JSON payload with file paths and file contents:
{
"format": "okf_bundle",
"okf_version": "0.1",
"generated_at": "2026-07-02T09:30:00Z",
"files": [
{
"path": "index.md",
"content": "..."
},
{
"path": "learnings/pattern/retry-malformed-json-responses-lrn-123.md",
"content": "..."
}
],
"summary": {
"status": "accepted",
"min_score": 4.0,
"matched": 12,
"exported": 8,
"skipped_low_score": 4
}
}The caller decides what happens next.
That is important. An MCP server should not silently publish organizational knowledge just because a lesson exists. Exporting and publishing are different steps.
What an Exported Lesson Looks Like
An exported learning becomes a Markdown document with YAML frontmatter.
The generated metadata includes OKF-facing fields:
---
type: ALMS Pattern
title: Retry malformed JSON responses
description: Some upstream responses include a trailing comma.
resource: alms://learnings/lrn-123
tags:
- api
- json
timestamp: "2026-07-02T09:20:00Z"
alms_learning_id: lrn-123
alms_learning_type: pattern
alms_score: 4.7
alms_resolution: open
alms_status: accepted
ai_generated: false
---The body keeps the actual lesson readable:
# Lesson
Some upstream responses include a trailing comma. Strip the trailing comma before decoding, then retry the parse once.
# ALMS Provenance
- Learning ID: `lrn-123`
- Learning type: `pattern`
- Score: `4.70`
- Resolution: `open`
- Enrichment status: `accepted`This is not trying to claim more certainty than ALMS has.
It says: this was an ALMS learning, it passed the selected filters, here is its score and status, and here is the portable document.
Why Not Just Use Search?
Search helps an agent find relevant memory while it is working.
Export solves a different problem.
Search answers:
What should this agent know right now?
Export answers:
Which lessons are mature enough to leave ALMS and become portable organizational knowledge?
That difference is subtle but important. A memory can be useful to query before it is ready to publish. A raw observation can help a debugging agent without belonging in a shared OKF repository.
The bridge creates a promotion path:
- An agent stores a learning in ALMS.
- The learning is enriched, reviewed, or scored by whatever workflow the team uses.
- Mature lessons are marked
acceptedand given a useful score. okf.exportemits selected lessons as OKF bundle files.- A caller writes those files to a repository, opens a review, or distributes them to other agents.
ALMS remains the operational memory layer.
OKF remains the portable knowledge layer.
What This Does Not Do Yet
This part matters because it is easy to overstate the architecture.
The current bridge does not implement a full confidence engine. ALMS records have scores and enrichment metadata, and okf.export uses those fields. If a team wants a weighted confidence model, human approval gate, or automated evaluator, that belongs in the enrichment workflow around ALMS.
The current bridge does not synthesize new "wisdom" from many lessons. It exports existing accepted lessons. Synthesis is a higher-level capability.
The current bridge does not write to Git. That is deliberate. File publication needs review, ownership, and repository policy. ALMS should provide the bundle, not bypass the publication process.
The current bridge does not make OKF a runtime dependency for ALMS. ALMS can still operate as a learning store without exporting anything.
These constraints make the feature smaller, but they also make it safer.
The Useful Architecture
The architecture I think is worth pursuing has three layers:
| Layer | Role | Current ALMS Relationship |
|---|---|---|
| Knowledge | Curated docs, APIs, runbooks, policies | OKF is a good exchange format |
| Experience | Agent-discovered lessons from real work | ALMS stores and syncs this natively |
| Wisdom | Patterns synthesized across many lessons | Roadmap, not the current bridge |
The first bridge is from experience to knowledge.
Not all experience should cross that bridge.
The value is in being selective. Exporting everything would recreate the same problem in a different format. The useful path is to export lessons that are accepted, scored high enough, and scoped by query, type, or tags.
Why This Matters
Multi-agent systems fail quietly when learning stays local.
One agent discovers a workaround. Another agent repeats the original failure. A third agent writes a slightly different workaround. Eventually the organization has three partial memories and no shared knowledge.
The ALMS-OKF bridge gives that learning a path out:
- ALMS captures the operational lesson.
- The enrichment workflow decides whether it is mature.
okf.exportturns it into portable files.- OKF-compatible consumers can read it without sharing the ALMS database.
That is the real value.
Not smarter memory for one agent.
Shared learning across agents, tools, and teams.
Closing Thought
The mistake is treating documentation and memory as competitors.
They are different stages of the same lifecycle.
Experience starts messy. Some of it becomes reliable. A smaller subset deserves to become shared knowledge.
ALMS is useful at the messy, operational end.
OKF is useful at the portable, curated end.
The bridge is the promotion path between them.
References
- Open Knowledge Format - Google Cloud / GitHub
- Model Context Protocol - Specification
- ALMS Open Source Repository - github.com/ghassan-ai-projects/alms
Read more technical writing and case-study notes from the archive.
Read More Articles