Every Token Is Rent: Building an Agent That Doesn't Forget
The easiest way to waste money on LLM systems is to make them relearn the same reality over and over again.
I do not just mean token cost, although that matters. I mean the more expensive cost: repetition, context rebuild, duplicated analysis, and workflows that never really accumulate understanding.
That is what I mean when I say every token is rent. If your agent has to keep re-reading the same environment to become useful, you are paying again for knowledge the system should already have.
The Real Problem With Stateless Agents
Modern models are capable enough that people sometimes underestimate how fragile the surrounding workflow still is.
A session can look impressive in the moment and still leave behind almost no durable intelligence. Close the loop, lose the context window, start a new run, and the agent is effectively back at the beginning.
That is acceptable for lightweight chat use cases. It is a serious limitation for systems that need continuity across projects, incidents, codebases, or multi-step research.
If you want an agent to behave more like a collaborator than a vending machine, memory architecture stops being optional.
The Three Layers That Made This Work
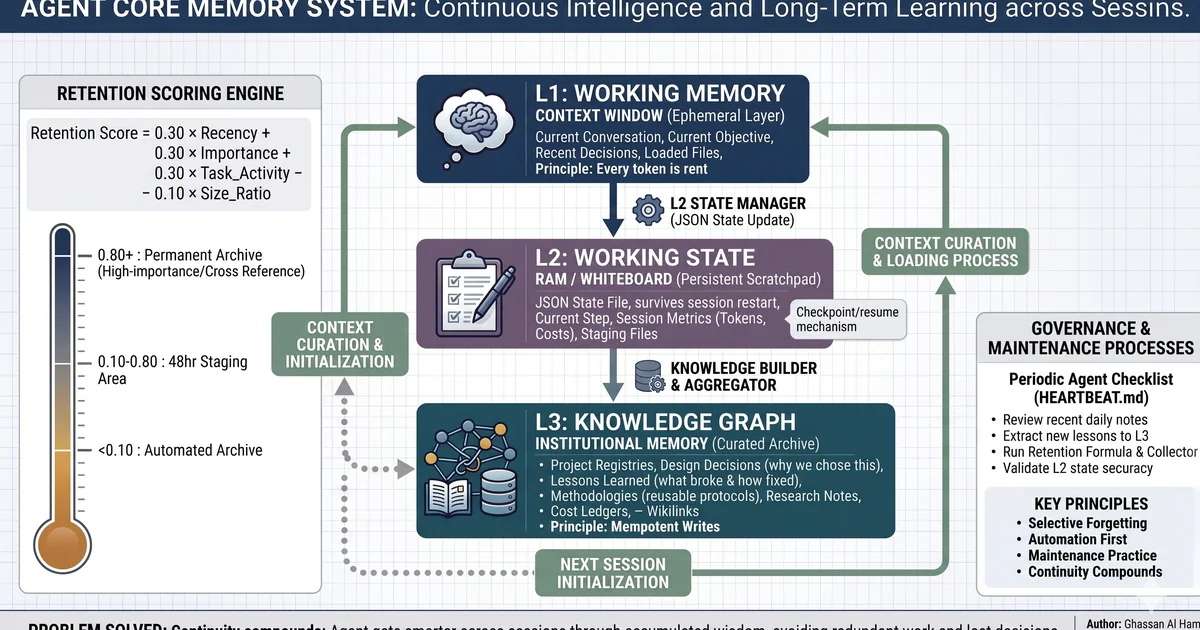
The model that worked best for me was not one giant memory bucket. It was a layered system with different responsibilities.
L1: working context. This is what the model sees right now. It should stay small, curated, and expensive by design.
L2: active state. This is the scratchpad for the current run: objective, progress, touched files, intermediate decisions, operational state.
L3: durable knowledge. This is where decisions, lessons, patterns, and reusable knowledge get promoted once they are worth keeping.
That separation matters because not everything deserves to live forever, and not everything that should live forever belongs in the prompt.
Why Most Memory Systems Get Bloated
A common mistake is to confuse storage with memory.
Logging everything feels safe, but it quickly creates a second problem: the system has too much to sift through and no clear notion of what deserves priority. At that point you have built a pile, not a memory system.
Useful memory is selective. It keeps what supports future work and lets the rest decay, archive, or stay retrievable without clogging the active loop.
That is why retention rules matter as much as capture rules.
What Selective Retention Changes
Once retention is treated as a first-class design choice, the system becomes calmer.
Important architecture decisions stay visible. Repeated failure lessons remain easy to recover. Active project context survives session boundaries. But stale noise stops competing for attention every time the agent wakes up.
That is the real productivity gain. Not some abstract promise of "long-term memory," but a workflow where the model spends less time reconstructing and more time progressing.
What the Automation Needs to Handle
The memory layer only works if the tedious parts are automated.
At minimum, I want the system to do three things reliably:
- update active state after meaningful work
- promote durable lessons into a structured knowledge layer
- archive or evict low-value material before it pollutes future sessions
If people have to remember to do all of that manually, the memory system becomes another neglected process. It needs to behave like infrastructure, not ceremony.
Why This Matters for Consulting Buyers
For engineering leaders, this is not just an AI design question. It is a cost and reliability question.
How much senior time is being spent re-explaining the environment to the system? How much model spend goes into rebuilding context that should already exist? How much inconsistency comes from workflows that forget yesterday's decisions?
Teams often chase better reasoning before they solve continuity. In a lot of real environments, continuity is the higher-leverage fix.
The Better Mental Model
I do not think of memory architecture as giving an agent a magical brain.
I think of it as giving the system a disciplined relationship with time.
What should remain local to this run? What should survive to the next one? What deserves to become reusable organizational knowledge? What should quietly disappear?
Once those questions are answered clearly, the agent stops feeling like a clever intern with daily amnesia and starts feeling more like a persistent system.
Where I Would Start
If I were helping a team improve this today, I would start very practically:
- define a minimal active-state layer
- create a durable place for decisions and lessons learned
- set explicit promotion and archival rules
- measure whether repeat context-loading begins to fall
You do not need a grand theory first. You need a workflow that stops paying rent on the same knowledge every session.
That is usually the point where the system begins to feel economically and operationally serious.
Read more technical writing and case-study notes from the archive.
Read More Articles