Issue Management as a System Property
For a long time, I thought strong incident handling meant being fast at reacting.
Good dashboards. Good alerts. Clear runbooks. A team that could jump on a problem quickly and get the system back on its feet.
That sounds mature until you notice the same classes of issues coming back every few weeks wearing slightly different clothes.
At that point, the problem is not response speed. The problem is that the system has learned nothing.
The Difference Between Monitoring and Issue Management
Monitoring tells you that something is wrong.
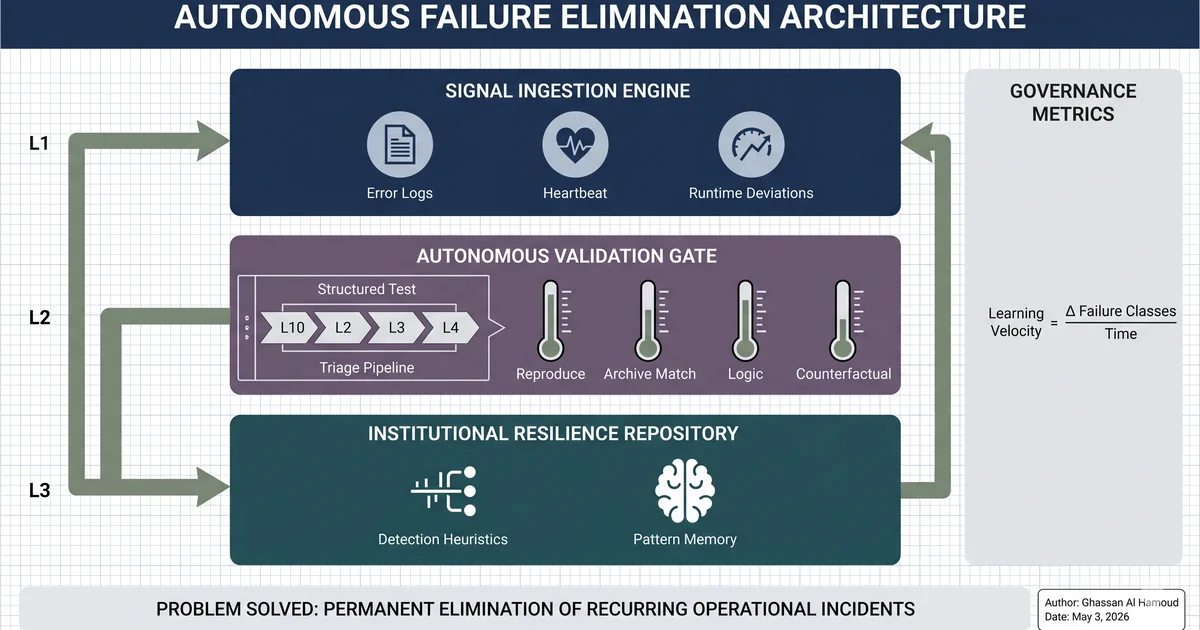
Issue management, if it is working properly, should answer four harder questions:
- what failed
- why it failed
- whether this pattern has happened before
- what changes will make that failure class less likely to return
A lot of teams stop at the first question. The pager goes off, the service is stabilized, the ticket is closed, and everyone moves on.
That is not issue management. That is controlled repetition.
The Shift That Changed My Thinking
The useful reframing was simple: treat issue management as a system property, not just an operating habit.
In practical terms, that means the system needs to do more than emit alerts. It needs to support a full loop:
- capture raw failure signals
- triage whether they are real, recurring, or just noise
- force a structured root-cause analysis
- verify that the fix actually removed the failure mode
- feed the result back into future detection
Once that loop exists, every issue becomes a chance to harden the architecture instead of a tax you keep paying forever.
The Part Most Teams Underestimate
The hard part is not collecting signals. Modern teams already have logs, traces, cron output, metrics, health checks, and enough dashboards to wallpaper a hallway.
The hard part is refusing shallow explanations.
I became much more skeptical of root-cause writeups that sound plausible but do not actually explain the chain. "Memory pressure" or "a bad deploy" is often just one layer above the symptom. It tells you where the pain showed up, not why the system was vulnerable in the first place.
So the gate has to be stricter than a postmortem ritual. A useful analysis should survive four tests:
- Can you reproduce the failure path from the proposed cause?
- Does it match or conflict with what previous incidents taught you?
- Does every step in the chain connect logically without hand-waving?
- If you remove this cause, does the failure become impossible or merely less likely?
If the answer is weak, the analysis is not finished.
The Metric I Care About Most
MTTR is useful. I do not dismiss it. Fast recovery matters.
But the more revealing measure is whether the system keeps forcing you to solve the same problem again.
That is why I care more about repeat-failure elimination than about incident theater. A team can have an impressive response culture and still waste enormous energy on recurring patterns that were never properly removed.
Once you look at it that way, the goal becomes much clearer:
not zero issues, but zero lazy repeats.
The Three Maturity Levels I See
The easiest way to explain this is in stages.
Reactive: humans detect or receive the alert, investigate manually, fix manually, and move on.
Proactive: detection improves, signals arrive earlier, but the analysis and remediation process is still mostly manual.
Self-improving: the system does not just detect. It helps classify, validate, document, and update future handling based on what it learned.
Most teams get stuck in the middle stage and call it maturity. It is better than chaos, but it still leaves a lot of resilience on the table.
Why This Matters for Engineering Leaders
If you are a CTO, VP Engineering, or platform lead, this is really a leverage question.
Do you want your team spending its senior attention on new architecture decisions, or on rediscovering why the same brittle edge case came back again?
When issue management becomes a system property, senior engineers stop serving as the only memory layer. The architecture starts carrying some of that burden itself.
That is especially important in AI-heavy systems, where failure can be semantic before it is technical. The workflow may remain "up" while quietly producing degraded output. If the system cannot identify, classify, and learn from that pattern, you are operating on borrowed confidence.
Where I Would Start
I would not start with a giant platform project.
I would start with one recurring failure pattern and force the full loop around it:
- instrument the signal clearly
- define a stricter root-cause template
- verify the fix against future recurrence
- update detection based on what was learned
If that works once, you can expand it. If it does not work once, a bigger platform will not save you.
The important shift is conceptual: stop treating issue management as a support function around the system. Start treating it as part of the system design itself.
That is when reliability begins to compound instead of reset.
Read more technical writing and case-study notes from the archive.
Read More Articles