How My Orchestrator Hands Off Coding Tasks to Qwen — The Agent Coordination Protocol That Makes It Work

One of the clearest lessons from building multi-agent systems is that specialization helps only if the handoff is disciplined.
It is not enough to have one model that is good at orchestration and another that is good at implementation. If the interaction between them is vague, you mostly just move confusion from one context window to another.
That is why I ended up caring so much about the handoff protocol itself.
Why a Single Agent Was the Wrong Shape
At first, the tempting design is obvious: give one powerful agent all the tools and let it handle the full path from idea to implementation.
Sometimes that works. But once the work spans product framing, architecture choices, implementation detail, and deployment, the tradeoffs get worse quickly. The same context window is trying to hold strategic intent and low-level coding concerns at once. The result is usually muddier than it looks.
In my case, the orchestrator was good at framing the problem and setting constraints. It was not the right component to write the implementation. Pushing it to do both made the system worse, not smarter.
What ACP Solves
The useful move was to separate roles and make the handoff explicit.
ACP, or Agent Coordination Protocol, is the pattern I used for that. The idea is simple: stop treating delegation as casual chat and start treating it as a structured contract between agents.
The orchestrator defines the objective, constraints, inputs, success conditions, and kill gates. The specialist responds with a plan, effort estimate, dependencies, and risk. The orchestrator then approves, revises, escalates, or kills the task.
That sounds almost boring, which is part of the point. It removes a lot of ambiguity before the expensive work begins.
Why Free-Form Chat Breaks Down
I do not think free-form agent conversation is useless. I do think it becomes fragile fast when the work has real execution consequences.
Three failure modes show up again and again:
- ambiguity compounds because the requirements keep being reinterpreted instead of restated cleanly
- roles blur because the specialist starts making product decisions and the orchestrator starts micromanaging implementation
- stopping conditions disappear because nobody defined when to escalate or abort
That is expensive in exactly the same way bad human process is expensive. The agent may continue producing tokens, but the system is no longer operating with clean accountability.
What a Good Handoff Needs
In practice, the handoff became much stronger once it answered a few non-negotiable questions up front:
- What are we trying to build?
- What constraints are fixed?
- What counts as success?
- What conditions should stop the work and push it back up?
Those questions matter more than any one model choice because they define whether the specialist can execute with confidence instead of improvising around missing assumptions.
Why This Matters Architecturally
The protocol is not just a communication convenience. It is an architecture boundary.
Once the orchestrator is responsible for framing and governance, and the coding agent is responsible for implementation, each layer can improve at its own job without constantly stepping on the other.
That also makes the overall system easier to audit. You can inspect what was requested, what was proposed, what was approved, and under which conditions the execution happened.
That is much closer to how serious engineering organizations already want work to move.
The Operational Layer Matters Too
The protocol is the contract. Here's the transport stack:
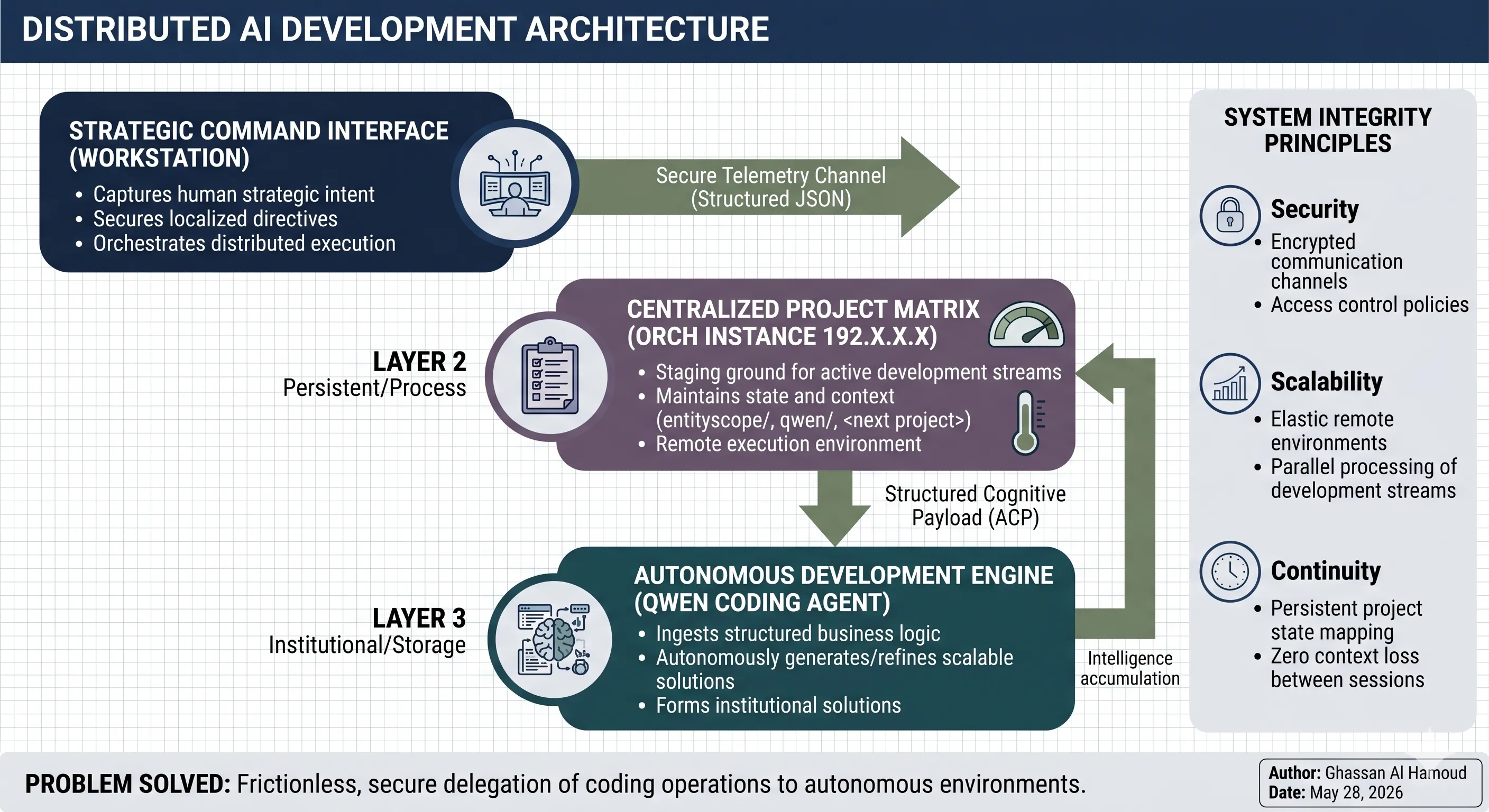
The orchestrator lives on my workstation. The coding agent runs on a separate machine at 192.X.X.X. They communicate via three layers:
- SSH for transport — file transfer and command execution
- MCP (Model Context Protocol) for tool access — the coding agent exposes MCP tools the orchestrator can invoke
- ACP for task handoffs — structured proposals and decisions ride over SSH/MCP
The coding agent needs no internet access. Just SSH to the project machine and a clear brief.
This separation is deliberate:
- Security: The coding agent touches only what's on the orch instance — zero access to my workstation
- Resource isolation: Heavy coding workloads don't compete with the orchestrator's reasoning context
- Session independence: The coding agent runs for hours. The orchestrator checks in, reviews, disconnects
The EntityScope Example
EntityScope was the moment this became more than theory.
The orchestrator had enough context to define the target system clearly. The coding agent had enough implementation focus to build it. ACP made the boundary usable.
Here is what that handoff looked like:
Proposal (Orchestrator → Qwen Code):
OBJECTIVE: Build DuckDB spine + MCP server for entity data
CONSTRAINTS: Python 3.11+, DuckDB, MCP SDK via pip
INPUT: Berlin Business Dataset CSV at ~/data/berlin_businesses.csv
Provisional schema at PP-003/03-discovery.md
SUCCESS: 1. entityscope_query returns results from DuckDB
2. entityscope_health returns green
3. All 4 MCP tools register and respond
KILL: >2 hours of wall time without a working health check
Dataset has <50K usable records after dedup
Response (Qwen Code → Orchestrator):
PLAN: 1. Define schema and load CSV
2. Build MCP server with 4 tools
3. Test each tool
RISK: CSV encoding issues (resolved: forced UTF-8)
MCP SDK version mismatch (resolved: pinned to 0.4.1)
EFFORT: ~45 minutes
DEPS: Nothing — all data is local
Decision (Orchestrator):
APPROVED — proceed
That structure did two valuable things at once: it reduced misinterpretation, and it made it obvious when the task was not ready for execution yet.
Why Consulting Buyers Should Care
If you are leading an engineering team, this is not really about whether one agent talked to another in a clever way.
It is about whether your AI workflow has explicit contracts, governance points, and role boundaries. Those are the same qualities that make other distributed systems easier to trust.
Without them, multi-agent design often turns into an expensive blur of partial autonomy. With them, it starts looking much more like controllable infrastructure.
The Broader Lesson
My takeaway is not that ACP is the only protocol shape that works.
It is that serious multi-agent systems need something stricter than vibes.
Once handoffs become structured, you get cleaner delegation, better auditability, clearer failure boundaries, and less wasted context. That is usually where the system stops feeling like a demo and starts feeling like engineering.
Read more technical writing and case-study notes from the archive.
Read More Articles