The ReAct Pattern
Reasoning and Acting in the Agent Era
Prerequisites
Reading time: 8 min | Last revised: 2026-06-28 | Version: 1.2
If You Only Read One Section
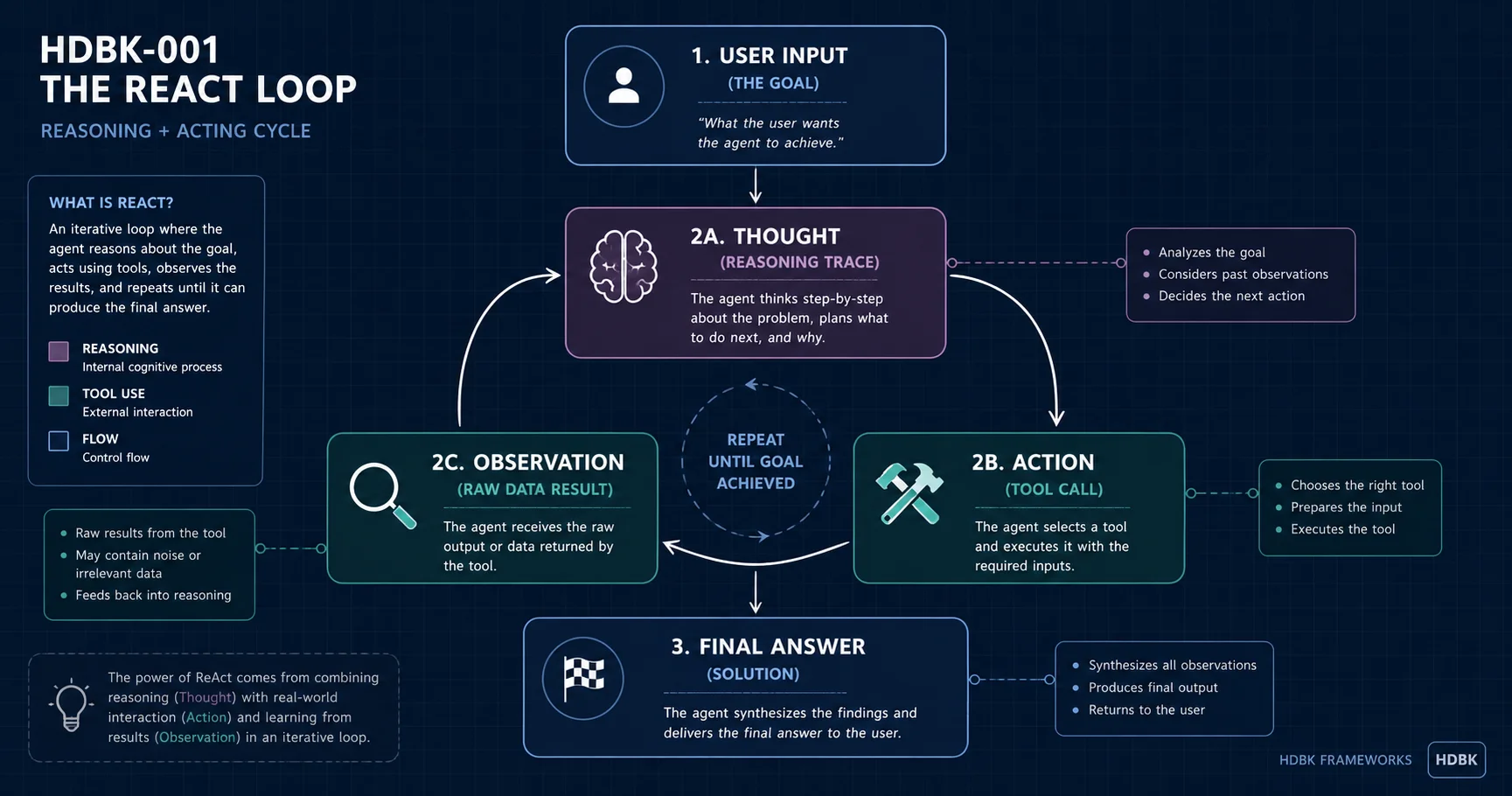
The ReAct (Reasoning + Acting) pattern is an iterative loop where an agent generates a Thought (reasoning trace), executes an Action (tool call), and receives an Observation (data). This interleaving allows the agent to update its internal strategy based on real-world feedback rather than following a static chain of thought.
Prerequisites
- Knowledge of basic LLM "Tool Calling" or "Function Calling" mechanisms.
- (Recommended) Chapter 0: The Agentic Landscape (Coming Soon)
The ReAct pattern is the architectural bedrock of modern autonomous agents. It formalizes how Large Language Models (LLMs) can interleave text generation with execution, bridging the gap between "thinking" and "doing."
The Core Loop: Thought → Action → Observation (TAO)
The power of ReAct lies in its systematic cycle, often referred to as the TAO loop:
- Thought: The agent analyzes the task and current state. It "thinks" about what tool it needs or how to interpret previous results.
- Action: Based on the Thought, the agent calls a specific tool (e.g., a search engine, a calculator, or a database).
- Observation: The system feeds the tool's output back to the agent as a new piece of context.
The Thought Trace
A Thought Trace is the verbal reasoning generated by the LLM before it commits to an action. Without it, agents are prone to "action-blindness," where they call tools without a strategy. The trace allows the agent to decompose goals, handle errors (e.g., "The search failed, I'll try a different query"), and track progress.
When to Use ReAct
ReAct is the right default when:
- The task is exploratory or multi-step (the agent cannot know the full path upfront).
- The answer depends on external, changing data (search, APIs, databases).
- The cost of a wrong answer is lower than the cost of over-engineering a plan.
Avoid ReAct when:
- The task is single-turn and deterministic (a plain prompt or RAG retrieval is cheaper).
- Latency is critical and tool calls add unacceptable delay.
- You can express the workflow as a fixed DAG (use Plan-and-Execute instead).
Example: Researching a Travel Itinerary
User request: "I have a 6-hour layover in Amsterdam. Can I visit the Rijksmuseum and still make my connecting flight?"
A ReAct agent might run this loop:
- Thought: I need to know the airport-to-museum transit time, current museum hours, and the departure gate closure time.
- Action:
search("Rijksmuseum opening hours today") - Observation: Open 09:00–17:00; last entry 16:30.
- Thought: I need transit time from Schiphol to the museum.
- Action:
transit_time("Schiphol Airport", "Rijksmuseum Amsterdam") - Observation: ~30–45 minutes each way by train.
- Thought: With 6 hours, 90 minutes round-trip + 2 hours visit + buffer leaves enough margin. I should still confirm the user's departure gate cut-off.
- Action:
ask_user("What time does your connecting flight board?") - Observation: User replies "21:30".
- Thought: The plan is feasible. I can now give a concise recommendation.
- Final Answer: Yes, you have time. Take the train from Schiphol to Amsterdam Zuid (≈30 min), visit the Rijksmuseum for up to 2 hours, and return with a 90-minute buffer before boarding.
Notice that the agent did not plan the whole trip upfront. It reasoned, acted, observed, and adapted after each tool result.
Implementation: The Skeleton Prompt
To enforce the ReAct pattern, the system prompt must explicitly define the expected format. Using structured tokens or XML tags can significantly improve parsing reliability.
Standard ReAct Template
You operate in a loop: Thought, Action, Observation.
Thought: [Your reasoning about the task]
Action: [tool_name]([arguments])
Observation: [The result of the action - provided by the system]
Rules:
1. Always generate a Thought before an Action.
2. Only call one tool at a time.
3. Wait for the Observation before the next Thought.
... (repeat until finished)
Final Answer: [Your conclusive response to the user]
ReAct in Action (Pseudocode)
For a technical builder, the ReAct loop is a stateful while loop that manages the conversation history.
def run_react_agent(user_input, tools, max_steps=10):
# Initialize state with system prompt and user goal
messages = [{"role": "system", "content": SYSTEM_PROMPT}]
messages.append({"role": "user", "content": user_input})
for _ in range(max_steps):
# 1. Thought + Action (Agent Turn)
response = llm.generate(messages)
messages.append({"role": "assistant", "content": response})
if "Final Answer:" in response:
return parse_final_answer(response)
thought, tool_name, tool_args = parse_react_format(response)
# 2. Observation (Environment/System Turn)
try:
observation = tools.execute(tool_name, tool_args)
except Exception as e:
observation = f"Error: {str(e)}"
# 3. Update Context for the next loop
messages.append({"role": "system", "content": f"Observation: {observation}"})
return "Error: Maximum iterations reached without final answer."
Common Pitfalls and Mitigations
| Challenge | Impact | Mitigation |
|---|---|---|
| Infinite Loops | High cost, no result. | Hard max_iterations limit (usually 5-10). |
| Action Formatting | Agent breaks the parser. | Use "Structured Outputs" (JSON mode) or rigid XML tags like <action>. |
| Context Bloat | High latency/cost. | Summarize long Observations or use a sliding window for the history. |
| State Drift | Agent forgets the goal. | Prepend the original goal to every prompt turn. |
| Hallucination | Agent invents tool results. | Strict separation: LLM writes Thought/Action; System writes Observation. |
Summary
- ReAct combines Reasoning (Chain-of-Thought) with Action (Tool-Use).
- The TAO loop (Thought-Action-Observation) makes agents resilient to external environment changes.
- Successful implementation requires a clear state management strategy and robust error handling for tool calls.
What's Next?
In Chapter 2: Plan-and-Execute, we move from reactive loops to proactive orchestration—learning how to handle larger, non-linear tasks where the agent creates a full roadmap before taking its first action.
Related Chapters
- Chapter 2: Plan-and-Execute — Solving the myopia problem.
- Chapter 3: Reflection — Adding self-critique to the loop.
Frequently Asked Questions
Q: Is ReAct the same as Chain-of-Thought? No. Chain-of-Thought only produces reasoning text. ReAct interleaves that reasoning with external actions and observations, so the agent can gather new information instead of reasoning in a vacuum.
Q: Can ReAct use multiple tools in one step? Classically, no. The original ReAct pattern generates one Thought and one Action per turn. Modern tool-calling APIs sometimes allow parallel tool calls; that is an optimization, but it complicates error attribution and debugging.
Q: How many iterations should I allow? Start with 5–10. More iterations increase cost and the risk of loops without proportional benefit. Add iteration caps, time limits, and explicit exit conditions.
Q: Do I need a special model to run ReAct? No. Any model with tool-calling support can run ReAct. Stronger models produce better Thought Traces and recover from errors more gracefully.
Glossary Terms Introduced
- ReAct: A pattern that interleaves reasoning and acting in a single loop.
- Thought Trace: The internal "scratchpad" reasoning of an agent.
- Observation: The external feedback or tool output provided to the agent.
- TAO Loop: The iterative cycle of Thought, Action, and Observation.
- Context Bloat: When the accumulated history of thoughts and observations exceeds the efficient processing limit of the LLM.
Revision History
| Version | Date | Changes |
|---|---|---|
| v1.2 | 2026-06-28 | Major Revision: Added state management pseudocode, prompt templates, and structural callouts based on peer review. |
| v1.1 | 2026-06-28 | Technical depth update. |
| v1.0 | 2026-06-28 | Initial draft. |
Building agent systems? Let's talk about how I can help your team.
Get in Touch