The Reflection Pattern
Self-Correction and Quality Control
Reading time: 8 min | Last revised: 2026-06-28 | Version: 1.1
If You Only Read One Section
The Reflection pattern adds a "second pass" to agentic workflows. Instead of delivering the first result it generates, the agent (or a separate Critic) reviews the output against a specific Rubric and suggests improvements. This simple loop is the single most effective way to reduce hallucinations and improve output quality without human intervention.
Prerequisites
- Chapter 1: The ReAct Pattern — understanding how agents generate thoughts and actions.
- (Recommended) Chapter 2: Plan-and-Execute — reflection is most powerful when layered on top of explicit planning.
In zero-shot prompting, an LLM has one chance to get it right. In agentic workflows, we give it a chance to look at its own work and say, "Wait, that's not quite right." This is the essence of Reflection.
1. The Architecture: Generator vs. Critic
Reflection typically involves two roles (which can be the same model or two different ones):
- The Generator: Produces the initial response, code, or plan.
- The Critic: Reviews the output against a checklist and provides specific feedback for improvement.
The "Yes-Man" Problem
A common failure mode in Reflection is the "Yes-Man" Critic, where the model simply agrees with itself to end the loop. To prevent this, the Critic must be given a Forced Critique instruction: "You are an elite senior editor. You must find at least 3 logical flaws or style violations in the text below. If it is perfect, explain why in the context of the rubric."
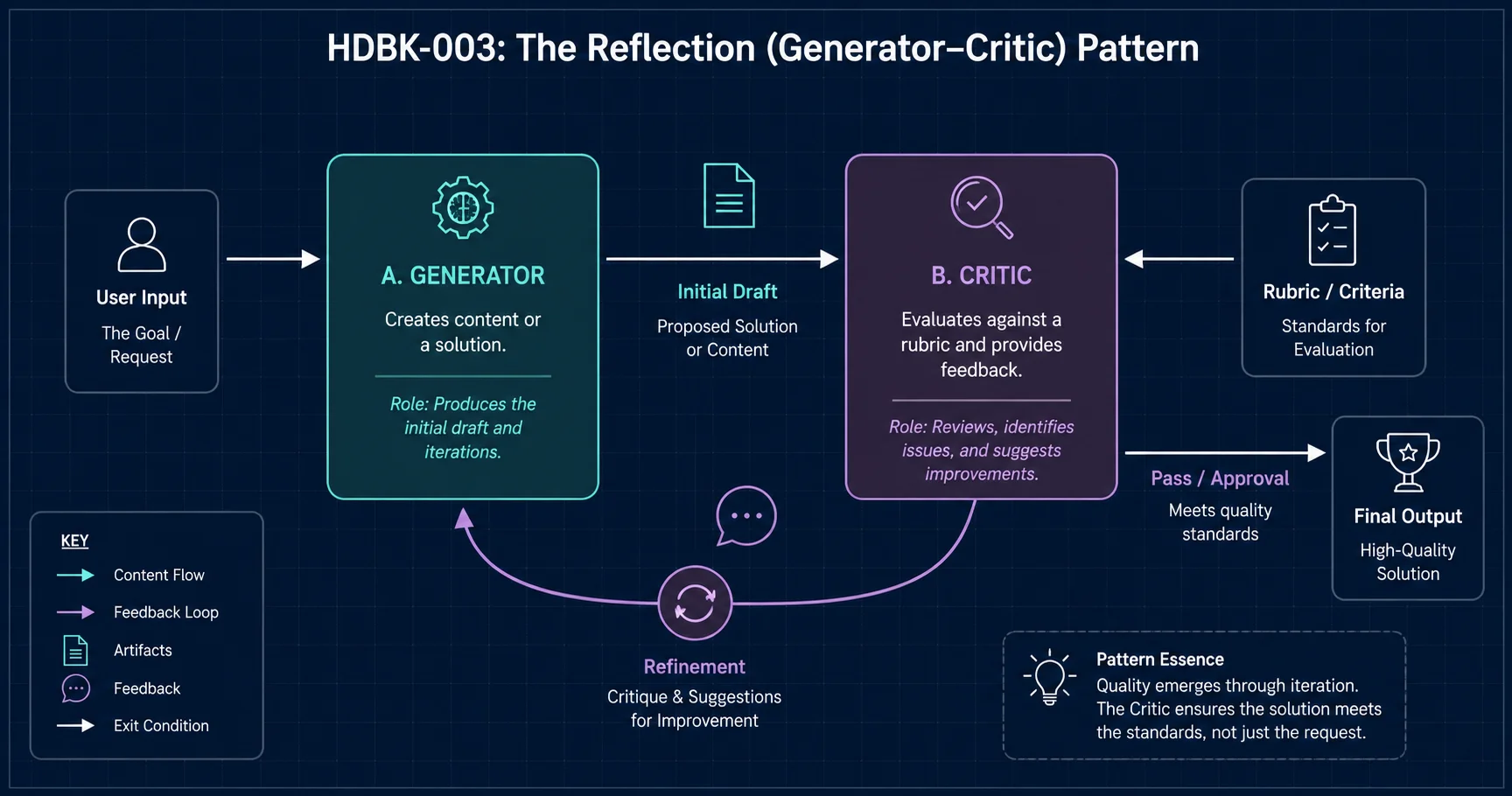
2. The Reflection Prompt Pattern: The Rubric
A successful Reflection Critic needs a structured rubric. General feedback like "make it better" results in vague improvements.
The Critic's Rubric Pattern:
Context: User Request + Initial Draft. Criteria: 1. Correctness: Are there logical fallacies or technical errors? 2. Completeness: Did the generator miss any part of the original request? 3. Efficiency: Is the solution the simplest way to achieve the goal? Output: List
[Critique], then[Actionable Improvement].
3. Implementation: The Refinement Loop
In technical tasks, Reflection is most powerful when combined with Deterministic Checks (like a Python linter or a compiler).
def generate_with_reflection(prompt, max_refinements=3):
# 1. Initial Generation
draft = generator.generate(prompt)
for i in range(max_refinements):
# 2. Hybrid Critique (Tool + LLM)
linter_errors = linter.check(draft) # Deterministic check
critique = critic.analyze(draft, linter_output=linter_errors)
if critique.score > 0.95 and not linter_errors:
break
# 3. Refinement
draft = generator.refine(draft, feedback=critique, errors=linter_errors)
return draft
4. Where to Place Reflection in the Pipeline
Reflection is not a standalone pattern—it is a quality gate that can be inserted at multiple points:
- After each ReAct step: Review the thought/action/observation before continuing. Cheap but can slow down fast tool chains.
- After each plan task: Review a completed task result before the Re-Planner marks it done. Good for Plan-and-Execute workflows.
- After the full output: Review the final answer before returning it to the user. Highest impact for user-facing quality.
- Continuously during generation: Streaming critic checks (advanced, higher cost).
Start with a final-output critic, then move upstream only if errors keep escaping.
5. Types of Reflection
| Type | Mechanism | Best For |
|---|---|---|
| Self-Reflection | Same model, new prompt turn. | Low-cost formatting & typo checks. |
| External Reflection | Larger/Specialized model (e.g., GPT-4o-mini to Claude 3.5). | Logic, security, and architectural review. |
| Deterministic | Compilers, Linters, Unit Tests. | Syntax, broken links, and functional correctness. |
6. When to Use Reflection
Use Reflection when: - The output is high-stakes (code, architecture decisions, public-facing content). - A deterministic verifier (test, linter, type checker) can catch errors the generator might miss. - You can write a specific rubric rather than asking the model to "make it better."
Skip Reflection when: - The task is low-stakes chat where latency and cost matter more than perfection. - You do not have an objective rubric (the Critic will drift into subjective noise). - The Generator is already good enough and the marginal gain is not worth the extra LLM calls.
7. Example: Generating a Configuration File
User request: "Generate a Kubernetes Deployment manifest for our API service."
- Generator produces a draft manifest with 3 replicas, a liveness probe, and resource limits.
- Deterministic Check runs
kubevaland finds a missingapiVersionfield. - Critic reviews the manifest against a rubric:
- Correctness: Are required fields present?
- Completeness: Did it include resource requests and probes?
- Security: Does it run as non-root?
- Critic output: "Missing
apiVersion; resource requests are present but limits are not; container runs as root." - Generator refines the manifest with
apiVersion: apps/v1, resource limits, and arunAsNonRoot: truesecurity context. - The loop repeats until
kubevalpasses and the Critic score exceeds the threshold.
This is a typical technical Reflection loop: deterministic tools catch the obvious errors, and the LLM Critic catches the semantic ones.
8. Common Pitfalls
- Oscillation: The agent fixes one thing and breaks another, looping indefinitely. (Mitigation: Implement a
max_refinementscap and a history of previous critiques). - Over-Correction: The Critic suggests changes that are purely subjective, leading to a "bland" output. (Mitigation: Use a strict, objective Rubric).
- Cost Accumulation: Every loop is a full LLM call. (Mitigation: Only use Reflection for high-stakes outputs, not routine chat).
Summary
- Reflection is a "Generator-Critic" loop that catches errors before they reach the user.
- A Forced Critique prevents the "Yes-Man" problem where agents agree with their own errors.
- Deterministic Tools (linters, tests) should be the first line of defense in technical reflection.
What's Next?
In Chapter 4: Multi-Agent Collaboration, we will see how to scale this into entire teams of specialized agents working together.
Related Chapters
- Chapter 1: The ReAct Pattern
- Chapter 2: Plan-and-Execute
Frequently Asked Questions
Q: Can the Generator and Critic be the same model? Yes, but it increases the risk of the "Yes-Man" problem. Use a different system prompt, temperature, or model for the Critic whenever possible.
Q: What should a rubric contain?
A good rubric has 3–5 objective criteria (Correctness, Completeness, Efficiency, Security, Style) and a forced output format such as [Critique] → [Actionable Improvement].
Q: How many reflection iterations are enough? Usually 1–3. Beyond that, you hit diminishing returns and rising oscillation risk. Always cap iterations and track the critique history.
Q: Is Reflection only for code? No. It works for any structured output: documents, plans, emails, design decisions, and even other agents' outputs.
Q: How is Reflection different from a simple "review this" prompt? Reflection is structured: it uses a rubric, a feedback loop, and usually deterministic checks. A one-shot review has no iteration and no explicit quality gate.
Glossary Terms Introduced
- Generator: The agent role responsible for the initial creation.
- Critic: The agent role responsible for evaluation and feedback.
- Deterministic Check: A non-LLM tool (like a linter) used to verify accuracy.
- Yes-Man Critic: A failure mode where the critic agent blindly approves the generator's work.
Revision History
| Version | Date | Changes |
|---|---|---|
| v1.1 | 2026-06-28 | Major Revision: Added "Forced Critique" pattern, Linter integration in pseudocode, and expanded Rubric details. |
| v1.0 | 2026-06-28 | Initial draft. |
Building agent systems? Let's talk about how I can help your team.
Get in Touch